華為HCIP-Big Data學習筆記(二) 大數據離線處理場景化解決方案之數據處理與存儲支持服務
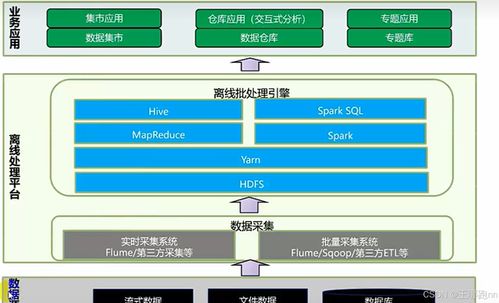
在大數據離線處理的復雜生態中,數據處理與存儲支持服務構成了整個解決方案的基石。它們是數據從原始狀態流向價值洞見的關鍵支撐層,確保了離線批處理任務的可靠、高效與可管理。本章將深入探討華為FusionInsight HD平臺在此領域提供的核心服務組件。
1. 數據采集與傳輸:Flume與Loader
離線處理的第一步是將分散的數據匯聚到統一的數據湖或倉庫中。華為平臺主要集成和增強了以下服務:
- Flume:一個高可靠、高可用的分布式海量日志采集、聚合和傳輸系統。其核心優勢在于基于流式數據的簡單靈活架構,通過配置Source、Channel、Sink即可實現從Web服務器、應用日志等數據源到HDFS、HBase等目的地的穩定傳輸,非常適合處理實時產生的日志類數據。
- Loader:華為提供的一個數據遷移工具,它實現了關系型數據庫(如Oracle, MySQL)與Hadoop生態(HDFS, HBase, Hive)之間的雙向批量數據導入導出。Loader通過MapReduce作業并行處理數據,支持全量與增量加載,并提供了圖形化界面,極大地簡化了結構化數據的遷移工作。
2. 分布式存儲基石:HDFS與HBase
匯聚后的數據需要可靠的存儲底座。
- HDFS (Hadoop Distributed File System):離線處理的默認存儲層。它將超大文件分割成塊,分布式存儲于集群的多個節點上,并提供多副本機制保障數據高容錯性。其“一次寫入,多次讀取”的模型非常契合離線批處理場景,為MapReduce、Spark等計算框架提供了高吞吐量的數據訪問能力。華為版本在原有基礎上增強了安全特性、NameNode高可用(HA)以及性能優化。
- HBase:構建在HDFS之上的分布式、面向列的NoSQL數據庫。它適用于需要隨機、實時讀寫訪問超大規模數據集(如海量詳單查詢、用戶畫像存儲)的場景。HBase通過行鍵提供快速查詢,是離線處理結果存儲或作為某些處理過程中間存儲的重要選擇。
3. 資源管理與作業調度:YARN
YARN (Yet Another Resource Negotiator) 是Hadoop 2.0引入的集群資源管理與作業調度框架,它將資源管理和應用程序監控分離開來。在離線處理場景中:
- ResourceManager (RM):作為集群資源的全局管理者,負責處理客戶端請求、啟動/監控ApplicationMaster、以及協調各個NodeManager的資源分配。
- NodeManager (NM):每個節點上的代理,負責管理單個節點上的資源(CPU、內存)和容器(Container)生命周期。
- ApplicationMaster (AM):每個提交的應用程序(如一個MapReduce作業)獨有的管理者,負責向RM申請資源,并與NM協作來執行和監控具體的計算任務。
通過YARN,多種計算框架(MapReduce, Spark, Hive等)可以共享集群資源,高效、有序地運行,避免了資源沖突,是支撐多任務離線批處理的核心。
4. 數據處理引擎:MapReduce與Spark
這是執行離線計算邏輯的核心。
- MapReduce:經典的分布式計算編程模型。它將計算過程抽象為Map(映射)和Reduce(歸約)兩個階段,中間通過Shuffle過程連接。其優勢在于編程模型簡單、容錯性強,特別適合處理超大規模數據集的批量計算(如全網日志分析、歷史數據統計)。但其多階段落盤的特性導致迭代計算效率較低。
- Spark:基于內存計算的通用分布式計算框架。它提供了比MapReduce更豐富的操作算子(Transformations和Actions)和更優的執行引擎。通過將中間結果緩存到內存中,Spark在迭代計算(如機器學習算法)、交互式查詢等場景下比MapReduce快數十倍。Spark Core是其核心,其上構建了Spark SQL(結構化處理)、Spark Streaming(流處理)等模塊,實現了離線與準實時處理的統一。在華為解決方案中,Spark得到了深度集成與性能優化。
5. 數據倉庫與SQL化處理:Hive
Hive是基于Hadoop的數據倉庫工具,它將結構化的數據文件映射為一張數據庫表,并提供類SQL(HiveQL)查詢功能。對于熟悉SQL的數據分析師而言,Hive極大地降低了大數據處理的門檻。其本質是將HiveQL語句轉換成一個或多個MapReduce或Spark作業在集群上執行。它適用于海量歷史數據的離線統計分析、報表生成等場景。華為FusionInsight中的Hive在易用性、性能和安全方面進行了大量增強。
###
數據處理與存儲支持服務層,通過Flume/Loader實現數據匯集,依托HDFS/HBase提供堅實存儲,由YARN統一調度資源,最后通過MapReduce/Spark/Hive等引擎完成計算。這些服務相互協作,共同構成了一個完整、高效、可擴展的大數據離線批處理流水線,為上層的數據分析、挖掘應用提供了強大的基礎設施支持。理解各組件定位與協作關系,是設計和優化離線處理方案的關鍵。
如若轉載,請注明出處:http://m.tgqfw.cn/product/5.html
更新時間:2026-06-19 21:30:23